Kaggle猫狗大战
项目报告
在本次项目中,将主要采用卷积神经网络和迁移学习的方法来实现猫狗图片的识别任务。
猫狗识别是典型的计算机视觉处理类问题,目前在深度学习领域,比较好的解决方法有卷积神经网络。同时,从机器学习的角度来说,猫狗项目属于监督学习的一种,是一种分类算法,这里的标签就是图片是猫还是狗,属于用深度学习来实现二分类。
领域背景知识
-
卷积神经网络(CNN):
卷积神经网络一般包括,卷积层,池化层,还有就是全连接层。下图为某一鸟类图片卷积网络处理过程。
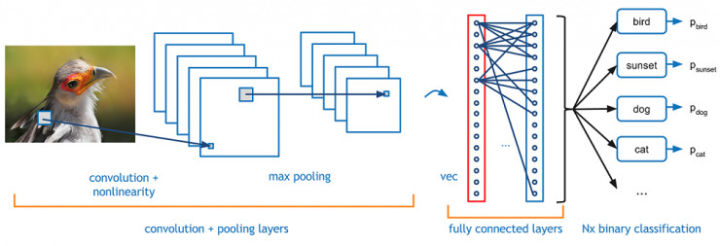
局部连接是指每个神经元只与上一层的一个局部区域连接,该连接的空间大小(滤波器的空间尺寸)叫做神经元的感受野(receptive field)。
卷积核(或者叫滤波器)的映射原理,就是所谓的卷积操作。卷积操作的目的就是为了提取特征。可以使用多个卷积核,进行多特征操作。
多层卷积,就是在模型中实现多个卷积层,多层卷积的目的是一层卷积学到的特征往往是局部的,层数越高,学到的特征就越全局化。
权值共享:当前层在深度方向上每个channel的神经元都使用同样的权重和偏差。这里作了一个合理的假设:如果一个特征在计算某个空间位置(x,y)的时候有用,那么它在计算另一个不同位置(x2,y2)的时候也有用。
卷积神经网络的局部连接和权值共享降低了参数量,使训练复杂度大大下降,并减轻了过拟合。同时权值共享还赋 予了卷积网络对平移的容忍性。
池化层的降采样输出参数量,并赋予了模型对轻度形变的容忍性,提高了模型的泛化能力。
全连接层,一般包含激活函数,完成特征的非线性映射,起到分类器的作用。
迁移学习和微调:
迁移学习:在ImageNet上得到一个预训练好的ConvNet网络,删除网络顶部的全连接层,然后将ConvNet网络的剩余部分作为新数据集的特征提取层。这也就是说,我们使用了ImageNet提取到的图像特征,为新数据集训练分类器。
微调:更换或者重新训练ConvNet网络顶部的分类器,还可以通过反向传播算法调整预训练网络的权重。
为什么使用迁移学习和微调?
从头开始训练一个卷积神经网络,不仅需要大规模的数据集,而且会占用大量的计算资源。比如,为了得到ImageNet ILSVRC模型,Google使用了120万张图像,在装有多个GPU的服务器上运行2-3周才完成训练。
在实际应用中,深度学习相关的研究人员和从业者通常运用迁移学习和微调方法,将ImageNet等数据集上训练的现有模型底部特征提取层网络权重传递给新的分类网络。这种做法并不是个例。
本次项目该选择哪种方法?
首先数据集的数量比之前imagnet的数据集小的多,而且种类就分成两类,属于动物图片识别,因此采取的方法就是使用预训练模型提取特征,然后重新设置新的分类器,进而搭建简短有效的模型来完成任务。如果预期的指标没有完成的话,那么可以考虑通过数据增益的方式来加大训练集的图片数量,或者进一步通过微调的方式来完善模型。
数据集和输入
Kggle官方数据集,训练集25000张图片,猫狗各一半,测试集12500张图片,猫狗比例不详。为三通道彩色图片。
如下所示为训练集中的图片,每张图片的尺寸大小并不一样,下面的x,y坐标是以150像素为单位,可能看出在图片的长短上有的不到200像素,有的已经超过450像素。在项目中,将使用Keras的图片预处理类来规范图片的大小,比如预处理模型常用到的(224,224,3)或者(299,299,3)的格式,这样才能满足卷积网络模型的的输入要求。
.jpg)
另外,关于由于训练集的图片是放在一起,没有分开,那么在项目中训练模型时,将采用validation_split=0.2的参数对训练集和验证集进行拆分。
解决方案描述
项目本身将采用Keras+Tensorflow+aws p2.xlarge服务器来完成
基准模型
下面是Keras官方预训练模型的列表,从中选择三个top1和top5分数都比较高的模型来进行实验,以达到预期目标为根本原则。目前预期,所选择预训练模型的所生成的对数损失应该可以满足基准阈值的要求。
关于模型的基准阈值,Kaggle的前10%的排名,截止到目前为止,在 Public Leaderboard 上的 logloss 要低于 0.06。
.jpg)
评估指标
本次项目以Kaggle官方提出的对数损失的评价标准,项目要求分数应进前10%,大约分数在0.05左右能够满足要求。
(话说下面为啥公式显示不出来呢?)
项目策略
第一步,首先使用Keras的图片预处理函数对图片进行处理,从图片文件转换成图片数据,然后生成深度CNN模型所需要的数据输入批次。
第二步,找一个预训练模型,这个选择ResNet50,,因为其全连接层的分类器的数量是1000。所以把这个分类器去掉,抽取特征。并且把这个瓶颈特征保留在h5py文件当中。
第三步,提取瓶颈特征中的作为新模型的输入,在新模型中添加新的FC(全链接层),也就是新的分类器,这个分类器的种类设置成1,也就是接近1的算是狗,接近0的算是猫,对模型进行编译(选择不同的优化器进行测试),在训练集中划分出20%的部分作为验证集。
第五步,模型训练,查看训练结果loss值的生成,选择不同的优化器进行优化。模型验证。
第六步,使用模型进行测试集的预测,并生成对应的预测文件。查看预测效果。
参考文献
[1] ImageNet Classification with Deep Convolutional Networks
[2] Rethinking the Inception Architecture for Computer Vision
[3] Deep Residual Learning for Image Recognition]
[4] Xception: Deep Learning with Depthwise Separable Convolutions]
[5] https://keras.io/zh/